はじめに
論文を網羅的に分析する場合に,bibtex の一覧を表に変換したいことがあります.時間がたつとその際の手順を忘れてしまうので,メモ書き程度に残しておくことにしました.
bibtex形式で論文一覧のexport
私の場合は,論文リストと概要が両方ともほしかったため, Scopusの検索ページ で該当しそうな論文を検索した後,以下のように設定しました (Google scholarでは,bibのダウンロードはできますが,abstractなどを含ませることができません).
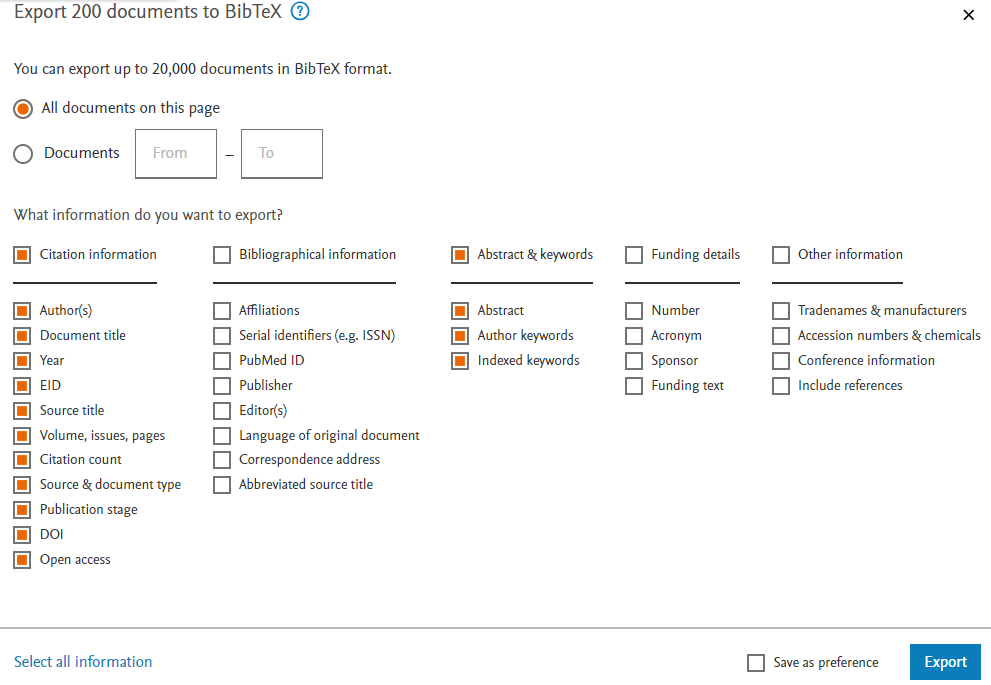
すると,末尾が .bib となるファイルが得られるので,適宜好きな名前で保存します.(scopusを使うためのアカウント契約が必要な可能性もあるそうなので,要確認.私は大学のアカウントでログインしています)
Pythonで bibtex一覧をcsvに変換するコード
bibtexparser というライブラリを用いて,以下のプログラムを作成しました.
bibの記述ごとに特定のkeyが含まれていたり,いなかったりというのがあるのですが (例えば国際会議版にはjournalにあるような号などの記述がないケースが多い),以下のように書くことで,各bib の行ごとに含まれるkeyのみを抽出していくことができます.
PandasのDataFrameに変換することで,ないkeyの部分は空白で埋めることができます.
import bibtexparser
import argparse
import pandas as pd
def main():
parser = argparse.ArgumentParser()
parser.add_argument("-f", "--file", help=' input file name(.bib): ')
args = parser.parse_args()
with open(args.file, encoding='utf-8') as f:
bibtex_text = f.read()
library = bibtexparser.parse_string(bibtex_text)
analysis_results_list = []
for entry in library.entries:
analysis_results = {}
for key in entry.fields_dict.keys():
analysis_results[key] = entry[key]
#print(entry.fields_dict)
analysis_results_list.append(analysis_results)
df_analysis = pd.DataFrame(analysis_results_list)
df_analysis.to_csv(args.file.split('.')[0] + ".csv")
if __name__ == "__main__":
main()
上のプログラムを以下のように実行すれば,同じ名前のcsvファイルが生成されます.
python bibtex-analyser.py -f [xx.bib]後は,このプログラムで得られるcsv ファイルをpandasなどで読み込んで,分析するプログラムを別に作るといいと思います.もちろん,Excelなどで開いて関数やフィルタなどの機能で分類するのもいいと思います.
おわりに
bibtexの一覧をcsvファイル等に変換する方法について説明しました.このようなまとめ方をするようになってから,なんとなく面白そうなものを見つけてよむという読み方だけではなく,読む前にその分野を概観して読むような読み方をしてみるようになったと思います.とある勉強会で,このようなExcelを作って動向調査をされている方のお話を聞き,なるほどと思って試してみました.興味のある分野や新規参入する分野の文献調査などに使っていきたいと思います.